Python 資料視覺化 - 使用 datashader
在做資料視覺化時,經常會遇到因資料量過大而無法簡單進行處理,或是執行速度過慢的問題。本文章將介紹一套Python上的資料視覺化工具datashader,能將數億個點的大資料快速生成視覺化圖形,並以New York Taxi Trip資料集為範例說明如何使用datashader繪製乘車位置分佈圖。
datashader
datashader是Python上一套基於Bokeh的圖形繪製Pipeline,並使用了numba套件以加速繪製效率,因此可以快速將大量資料轉換成視覺化圖形。
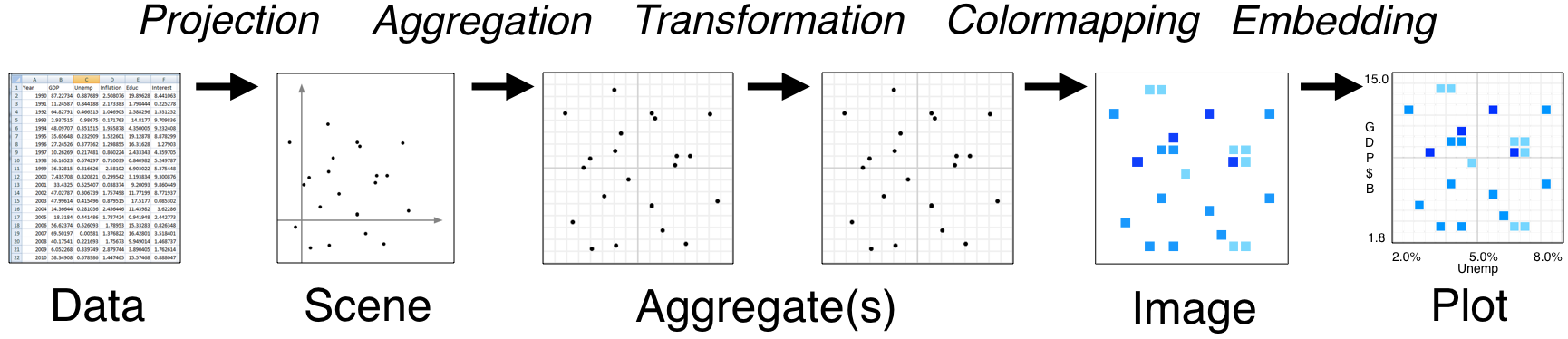
datashader 繪製圖片的過程主要可分為三個步驟:
- Projection - 選擇所要處理的資料,並設定繪製的圖片大小與資料範圍等。
- Aggregation - 統計原始資料並計算所對應的Grid性質。
- Transformation - 將統計完成後的資料以圖片方式呈現出來。
下圖為datashader的Pipeline)
安裝 datashader
如果有安裝Anaconda或Miniconda,可直接透過conda來安裝datashader套件
conda install -c bokeh datashader
或是直接從GitHub上安裝最新版本的datashader套件
conda remove --force datashader
git clone https://github.com/bokeh/datashader.git
cd datashader
pip install -e .
dask
一般在Python上處理資料時會使用Pandas這個套件來讀取資料並進行處理。但Pandas在使用時會先將資料完整讀取到記憶體內,當資料量非常巨大時常常會遇到out-of-memory問題。此外Pandas也因只能使用到單核心無法並行處理進而影響到效能。
因此若有上敘資源問題時,可以使用dask取代Pandas進行資料處理。Dask支援資料平行處理,將資料分成小部分執行,可避免出現記憶體不足的問題。此外因dask使用Pandas相似的使用者介面,熟悉Pandas的人很能很輕易熟悉dask的使用方式。
安裝 dask
與datashader相同,dask也可透過conda安裝
conda install dask
或是由GitHub上下載安裝最新版本手動安裝
git clone https://github.com/dask/dask.git
cd dask
python setup.py install
範例
Dataset
以下將使用Kaggle上的 2014 NYC Taxi Trip Dataset來當作展示展示範例。該資料集為2014年紐約的計程車乘車資訊,包含上下車時間與GPS座標等,在本範例中只使用乘客上車時的資料來展示。
若要從直接從 Linux terminal 上下載 Kaggle 上的檔案需附帶瀏覽器的Cookie資訊,方法可參照相關連結
Preprocessing
由於GPS座標為對應球面的座標系統,若要繪製二維平面時需將GPS轉換為2D平面座標。因此須先做資料前處理使資料能正確呈現。可以使用datashader.utils.lnglat_to_meters()函數將GPS座標轉換為Web Mercator格式。如下列範例
import datashader
# New York GPS coordinator
x, y = datashader.utils.lnglat_to_meters(longitude=-74.0059, latitude=40.7127)
執行後可得到 x = -8238299.103697925 與 y = 4970056.8929846436 的結果。分別代表由Greenwich往東以及由**Equator(赤道)**往北的距離(公尺)。以此方式將計程車資料集中的 pickup_longitude 與 pickup_latitude 欄位轉換為 pickup_x 與 pickup_y 欄位,並與 pickup_datetime 欄位一起另存為 nyc_taxi_data_2014_pickup.csv 檔案,以方便的之後的資料繪製。
Code
這裡我們透過 Pandas 套件讀取 CSV 檔為 Dataframe
# 匯入所需 Packages
import dask.dataframe as dd
import dask.diagnostics as diag
import datashader as ds
import datashader.transfer_functions as ds_tf
import numpy as np
from datashader.utils import export_image
from matplotlib.cm import hot
# 設定 NY taxi dataset 路徑
dataset = '{DATASET_FOLDER_PATH}/nyc_taxi_data_2014_pickup.csv'
# 設定讀取的檔案
df = dd.io.csv.read_csv(dataset)
使用df.head(n=3)可得到下列dataframe資料欄位
| pickup_datetime | pickup_x | pickup_y | |
|---|---|---|---|
| 0 | 2014-01-09 20:45:25 | -8237059.5 | 4973602.5 |
| 1 | 2014-01-09 20:46:12 | -8235682.0 | 4978972.5 |
| 2 | 2014-01-09 20:44:47 | -8236370.0 | 4973980.5 |
# 依照設定範圍,計算圖片寬度對應的高度
def calcCanvasHeightPixel(fix_width, x_bound, y_bound):
x_coff = abs(x_bound[0] - x_bound[1])
y_coff = abs(y_bound[0] - y_bound[1])
return int(fix_width * y_coff / x_coff)
# 參數設定
bound = ds.utils.lnglat_to_meters([-74.056273, -73.735558], [40.686604, 40.916272])
x_bound = tuple(bound[0])
y_bound = tuple(bound[1])
# 計算 Canvas 的 Pixel 寬高
width = 800
height = calcCanvasHeightPixel(fix_width=width, x_bound=x_bound, y_bound=y_bound)
# 建立 Canvas 物件
canvas = ds.Canvas(plot_width=width, plot_height=height, x_range=x_bound, y_range=y_bound)
## 使用 dataframe 資料建立 Aggregation 物件,並使用 ProgressBar 顯示處理進度。
with diag.ProgressBar():
agg = canvas.points(df, 'pickup_x', 'pickup_y')
# 建立影像物件並設定背景為黑色
img = ds_tf.shade(agg, cmap=hot)
img = ds_tf.set_background(img, color='black')
# 儲存為 png file
export_image(img=img, filename='nyc_taxi_2014_pickup', fmt='.png')
開啟儲存的nyc_taxi_2014_pickup.png圖片檔可得到以下結果
 New York City 2014年乘車地點分佈圖
New York City 2014年乘車地點分佈圖
