從圍棋到星海爭霸 - 淺談人工智慧的挑戰 (1)
從AI黎明期開始,如西洋棋(chess),圍棋(Go)或象棋等棋類遊戲一直是人工智慧的研究與測試領域。但由於早期的計算機的能力限制以及演算法的發展,較為複雜的棋類遊戲仍無法打敗世界級水準的棋手。直到1997年時IBM的深藍(Deep Blue)在西洋棋比賽中打敗了世界棋王Garry Kasparov,展現了電腦也能夠在西洋棋上打敗人類世界頂尖棋手的實力。
 Garry Kasparov與Deep Blue的西洋棋競賽(From: Stanford CS221 Page)
Garry Kasparov與Deep Blue的西洋棋競賽(From: Stanford CS221 Page)
雖然西洋棋已被Deep Blue攻克,但圍棋領域仍然屹立不搖。和西洋棋相比,圍棋的複雜度高上太多,如果以19x19的圍棋盤面大小來說狀態變化就有約
$$10^{172}$$種可能性。這是一個非常龐大的數量,即使是使用現代的Super Computer也在有限時間內列舉所有可能性。也因此圍棋一直被認為是電腦無法短時間內到達人類的頂尖水準。
AlphaGo - 深度學習技術展示
當各大公司如Facebook都推出自己的圍棋程式Darkforest時,一家被Google收購的英國AI公司DeepMind,卻以自家開發的AlphaGo直接對圍棋界頂尖的韓國棋手李世乭(Lee Sedol)發出了對弈挑戰,最後敲定2016年3月在韓國舉行比賽。
 AlphaGo與李世乭在首爾的人機大戰(From: Go Game Guru)
AlphaGo與李世乭在首爾的人機大戰(From: Go Game Guru)
一開始許多圍棋界人士認為,AlphaGo為要在圍棋領域擊敗人類世界頂尖棋手,現階段來說非常困難。但許多資訊領域的人士則認為AlphaGo有很大的勝率擊敗李世乭。但最後結果卻大出賽前的圍棋專家預料,AlphaGo以4:1擊敗李世乭。且在對弈的過程中AlphaGo展現出來許多令人無法理解,但卻能有效地達到獲勝的目的棋步。
Master - 網路上的圍棋幽靈Sai
在與AlphaGo對弈後一年,2017年1月中國圍棋網忽然出現了一位神秘棋手Master,在快棋規則下交出了驚人的60戰全勝,其中還包含了古力,井山裕太等知名圍棋棋士。也因為與圍棋漫畫棋魂中,藤原佐為藉由主角近藤光下網路圍棋打敗重大高手的情節相仿,因此Master也在網路上被戲稱是Sai再現(Sai是漫畫中藤原佐為使用的網路名稱)。在60勝後DeepMind也公布了Master就是升級版的AlphaGo,之後更在2017年5月的中國烏鎮圍棋峰會以3:0擊敗了當時世界排名第一 的柯潔。
 AlphaGo(Master)與柯潔的比賽
AlphaGo(Master)與柯潔的比賽
而比賽結束後DeepMind也宣布AlphaGo將引退不再參加圍棋比賽,並在網路上開放Master版AlphaGo的自我對弈棋譜,十足意味著AI已在圍棋領域封頂了。
AlphaGo的挑戰 - 最佳落子位置
強化學習(Reinforcement Learning)
有別專注在單一輸出結果的監督式學習(Supervised learning)與非監督式學習(Unsupervised learning),棋類遊戲中則是使用到強化學習(Reinforcement Learning)的概念。監督式學習的模型從輸入資料中得出得出一個結果,我們可以用那個結果檢證是否正確。但在強化學習中,單一輸出並不像監督式學習中那麼重要,真正重要的是**“一連串輸出後所得到的結果”**。因此強化學習注重的是,所有動作(Action)執行完後的結果是否符合預期,而棋類遊戲正好符合這樣的概念 - “觀察盤面狀態,決定下一手直到結束”。
 強化學習概念圖(From: Wikipedia)
強化學習概念圖(From: Wikipedia)
從途中可看出,觀察者觀察整個**環境(Environment)後,將現在的狀態(State)與回饋值(Reward)傳給代理人(Agent)依照策略(Policy)**決定下一步驟動作,不斷重複直到結束為止。
AlphaGo的架構
雖然Agent要決定的動作很單純,但圍棋的狀態複雜度非常高,要暴力解幾乎不可能。因此AlphaGo採用了兩個深度卷積神經網絡(CNN) - “策略網路(Policy Network)”與“值網路(Value Network)”。並配合蒙地卡羅樹狀搜尋(MCTS, Monte Carlo Tree Search)演算法,依照當前盤面進行評估最佳落子位置。
-
策略網路(Policy Network):輸入現在盤面狀態,預測下一步最可能下子位置。
-
值網路(Value Network):輸入現在盤面狀態,得出目前盤面勝率,可用來減少搜尋深度。
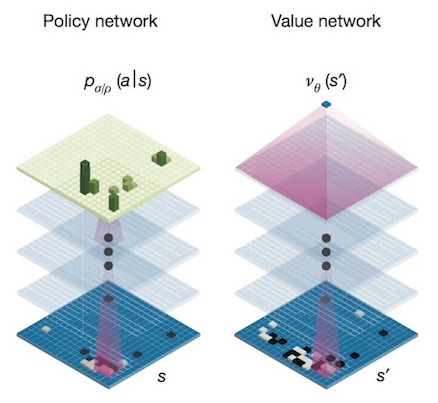 策略網路(Policy Network)與值網路(Value Network))
策略網路(Policy Network)與值網路(Value Network))
訓練步驟
-
由KGS(KGS Go Server)上的過去三百萬場以上的對弈資料,訓練策略網路
$$P_\sigma$$與快速下子策略網路
$$P_\pi$$。
-
以
$$P_\sigma$$為基礎,依勝率訓練強化學習策略網路
$$P_\rho$$。
-
由強化學習策略網路不斷的自我對弈,來學習價值網路
$$\nu_{\theta}$$
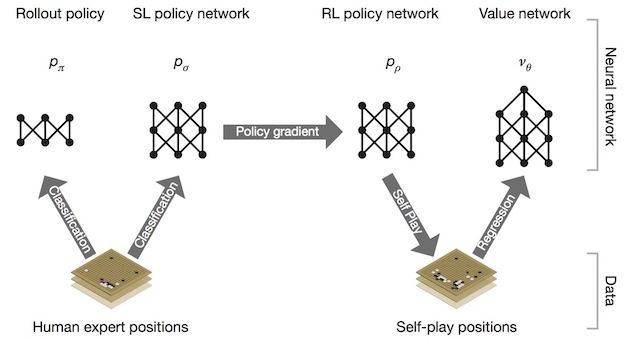 AlphaGo 訓練流程
AlphaGo 訓練流程
落子決策
AlphaGo在落子時,主要是依靠蒙地卡羅樹狀搜尋(MCTS)演算法提供決策框架。所謂的MCTS是一種啟發式搜尋演算法,時常用在遊戲內的決策系統。可分為四個主要步驟
-
Selection:從根節點R依照選擇策略,開始選擇連續的子節點,直到葉節點L為止。
-
Expansion:若是葉節點還不能判斷是否結束,則由該節點繼續往下建立新節點。
-
Simulation:從新節點進行模擬以決定該點的結果為何。(Ex.如0代表輸,1代表贏)
-
Back-propagation:將Simulation步驟得出的結果傳遞回跟節點R
AlphaGo則將訓練好的策略網路
$$P_\sigma$$,
$$P_\pi$$與值網路
$$\nu_{\theta}$$應用到MCTS中的Expansion與Simulation步驟,作為落子預測以及結果估計用函數,用以搜尋最佳落子位置。如下圖所示
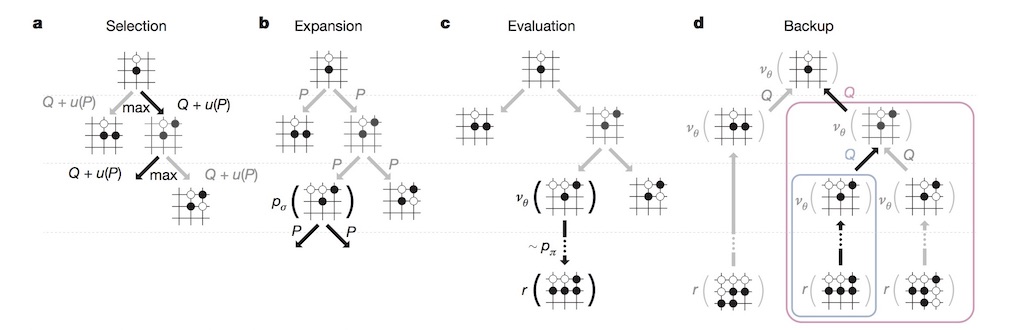 AlphaGo的蒙地卡羅樹狀搜尋架構
AlphaGo的蒙地卡羅樹狀搜尋架構
之後的Master版本仍延續了這個基礎架構,但不同的是DeepMind改善了演算法,效能前一版高出10倍,且並用新一代的TPU來進行運算(與李世乭對弈時用了50台併聯TPU,而與柯潔對弈只用了單機版TPU)。而最重要的改變,就是使用AlphaGo自我對弈的棋譜來進行策略網路的訓練,而不依賴人類初始結果,讓AlphaGo在不斷自我對弈中修正策略網路與值網路,進而達到更好的效果。
AlphaGo其實不聰明?
雖然AlphaGo雖然展現了超越人類頂尖圍棋手的能力,但是還是屬於弱人工智慧(Narrow AI)的範疇 - 即只能處理特定領域問題,並沒有考慮到更多面向的範疇。因此雖然能打敗世界圍棋高手,卻無法像IBM Watson一樣,去處理自然語言和人類語意,並在Jeopardy上打敗人類常勝冠軍,因兩者的演算法與系統截然不同。
此外西洋棋或圍棋在性質上是一個**完全資訊(Perfect information)**系統,所有所有雙方狀態與變化都是可以被觀測,不存在隱藏的狀態,此外也不存在系統中常有的雜訊狀態。不像撲克牌遊戲如德州撲克,存在著不確定對方手牌的狀況。因此對圍棋的挑戰,都是如何找出最適當的演算法,去減少計算複雜度與增加勝率。
此外一個人工智慧系統的行為,也與他的估值函數息息相關,AlphaGo採用了輸/贏來當作目標值,那演算法自然會尋找最穩的方式落子,因此在對弈中有人懷疑明明下另外一子可以贏更多目,但為何不做就是這個緣故。
在下一篇我們將會介紹DeepMind對星海爭霸2遊戲的挑戰,即DeepMind如何處理不完全資訊(Imperfect information)與以及多重代理人系統時,所遇到的問題與挑戰。
